 Computing likelihood ratios in the pattern comparison disciplines
Computing likelihood ratios in the pattern comparison disciplines
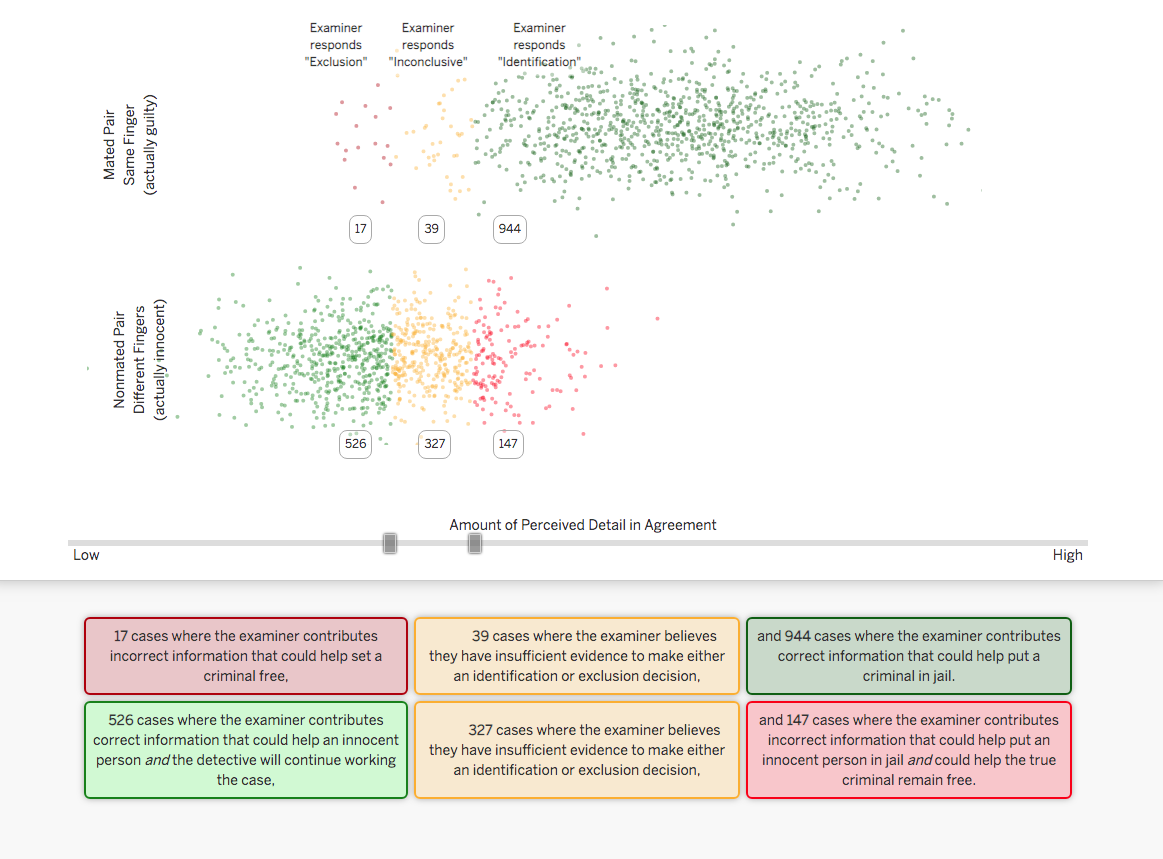
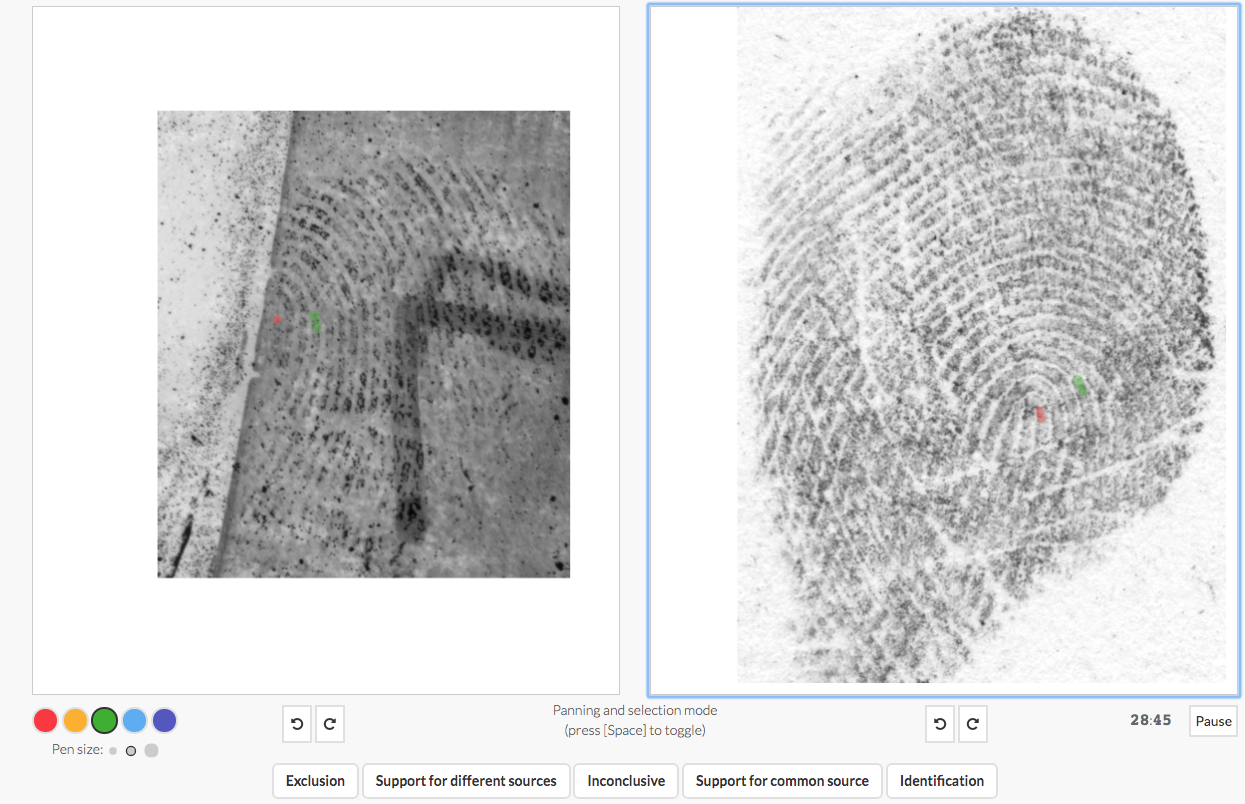
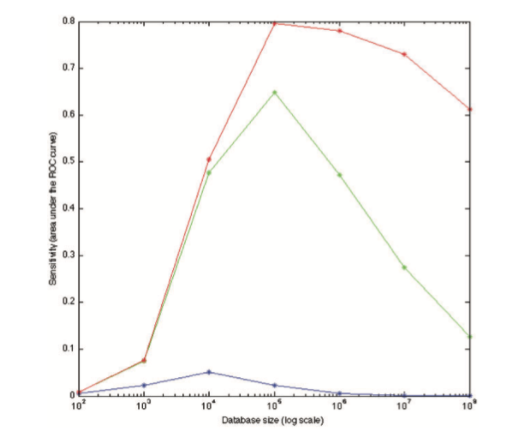
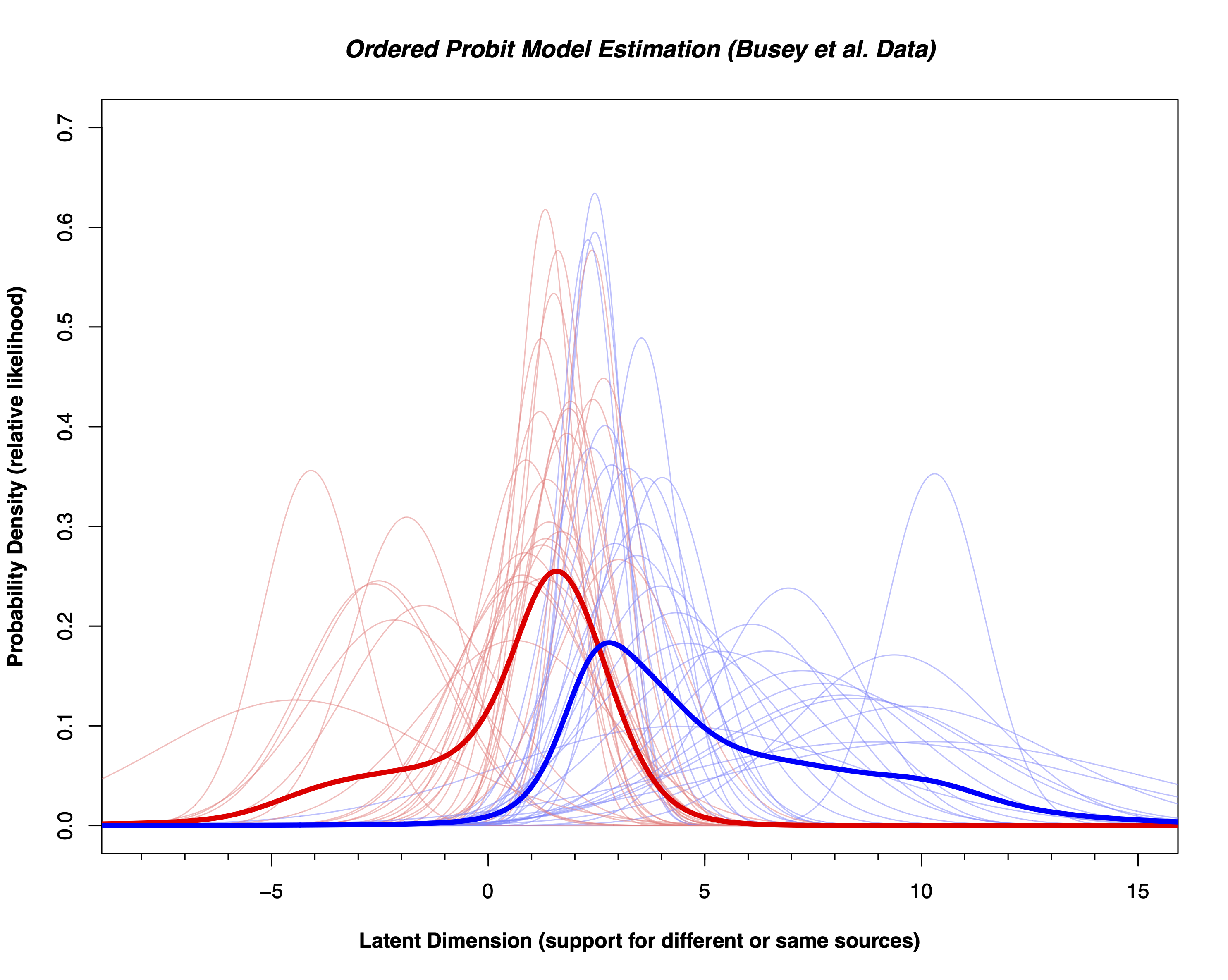
When you make an identification, you know that not all identification decisions are created equal. We also don’t know if the term ‘identification’ is calibrated to the strength of the evidence. In this paper we re-analyze data from our own lab and data from the FBI/Noblis black box study to convert the distribution of scores from all the examiners who completed this comparison into a numerical score called the likelihood ratio. This number accurately reflects the true strength of the evidence provided by all of the examiners who completed a particular comparison.
Read More