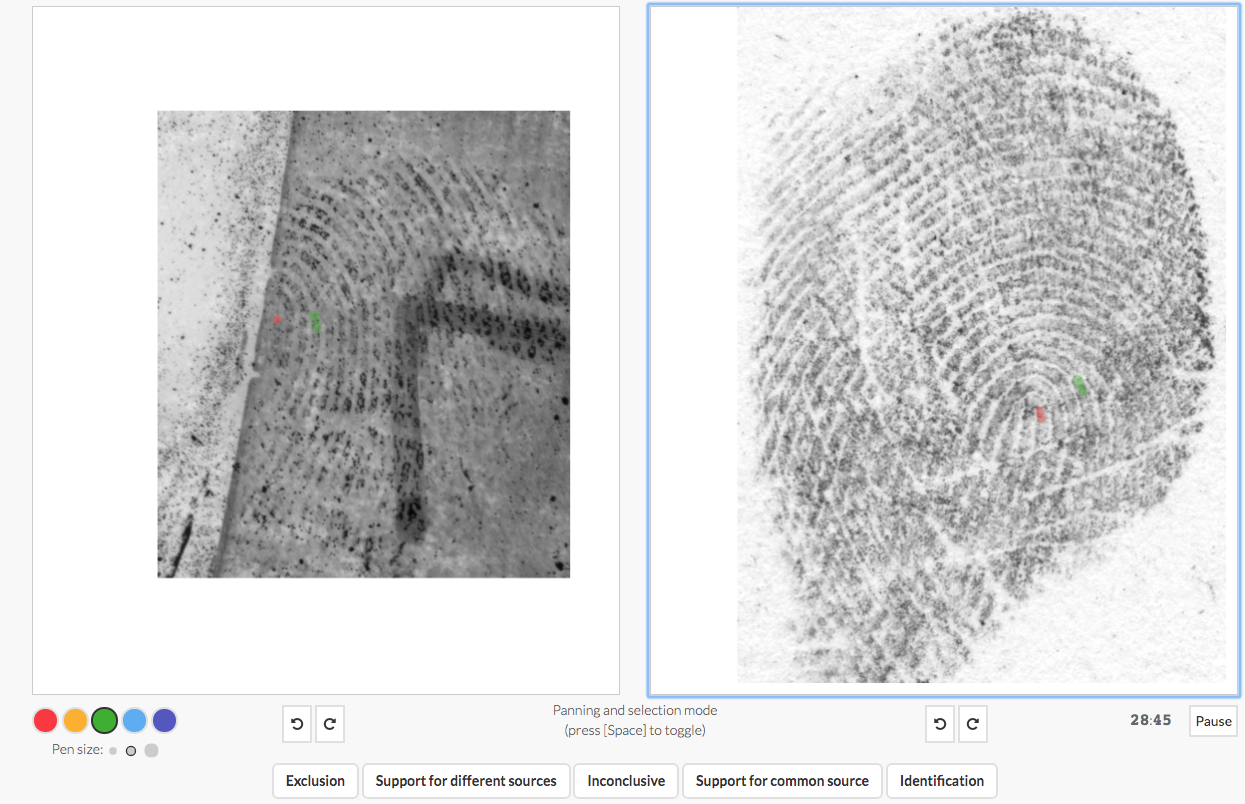
Varying the Size of the Conclusions Scale
How should conclusions be expressed?
When you conduct a comparison, you accumulate evidence in favor of one of two hypotheses:
-
the two impressions came from the same source
-
the two impressions came from different sources
However, if this accumulated evidence is expressed using one of three conclusions, information gets lost. That’s because unless you provide supporting information, a just barely over the threshold conclusion and a Helen Keller conclusion are treated as the same. Likewise, there are probably some near-threshold conclusions that you went inconclusive on, but really wished that you could have provided more information to the detective.
One solution to this problem is to expand the conclusion scale from 3 categories to 5 categories. We still keep the same Identification and Exclusion categories, but add in ‘Support for same source’ and ‘Support for different sources’ conclusions. These potentially would allow for investigative leads while not changing anything else.
In this project, we compared the tradition 3-conclusion scale to the expanded 5-conclusion scale. There are two potential dangers to increasing the scale:
-
Examiners might become objectively worse at distinguishing mated and non-mated impressions. This results from having to keep additional decision thresholds in mind; if they drift, that can reduce performance over time.
-
Examiners might redefine what they mean by ‘Identification’ with the expanded scale. This might be a problem because a case that moves to an arrest or a trial using the 3-conclusion scale might not proceed using the 5-conclusion scale. At the very least we want to know if this might happen.
We tested 27 latent print examiners using 60 comparisons, using displays like the one above. For each participant, half of the trials used the traditional scale and half of the trials used the expanded scale. Examiners knew on each trial which scale they would be using. We fit the data using variants of Signal Detection Theory. For more information on Signal Detection Theory, see here.
Conclusions
We found that examiners did not get objectively worse with the expanded scale, and that the new ‘support for..’ categories did provide useful investigative leads for many of the formerly inconclusive conclusions. However, examiners did seem to redefine what they mean by ‘Identification’, reserving it for only the strongest comparisons.
In addition, there were a fair number of what might be thought of as ‘erroneous support for common source’ conclusions. These are situations where an examiner might be comfortable only suggesting an investigative lead, but the detective treats it as a definitive conclusion. Care must be taken to educate the consumer that a stronger conclusion was available, but not used in this case.
For more information, the published article is in this pdf.
An additional article that replicates this work and expands it to strength-of-support scales and other disciplines is here: pdf.
Also see this companion piece, which addresses how different scales are interpreted by laypersons: pdf.